Apache Kafka – это один из самых популярных брокеров сообщений на рынке IT. Когда-то был разработан LinkedIn для своих внутренних нужд, позже был передан в OpenSource. В настоящее время главным мэинтейнером Apache Kafka является компания Confluent. Думаю на истории можно остановиться. Подробнее о Apache Kafka можно почитать здесь https://kafka.apache.org.
Какую проблему решает?
С одной стороны, когда мы имеем один источник данных и одного потребителя данных, то Kafka и другие брокеры сообщений нам вообще ни к чему. Примерно выглядит это вот так:
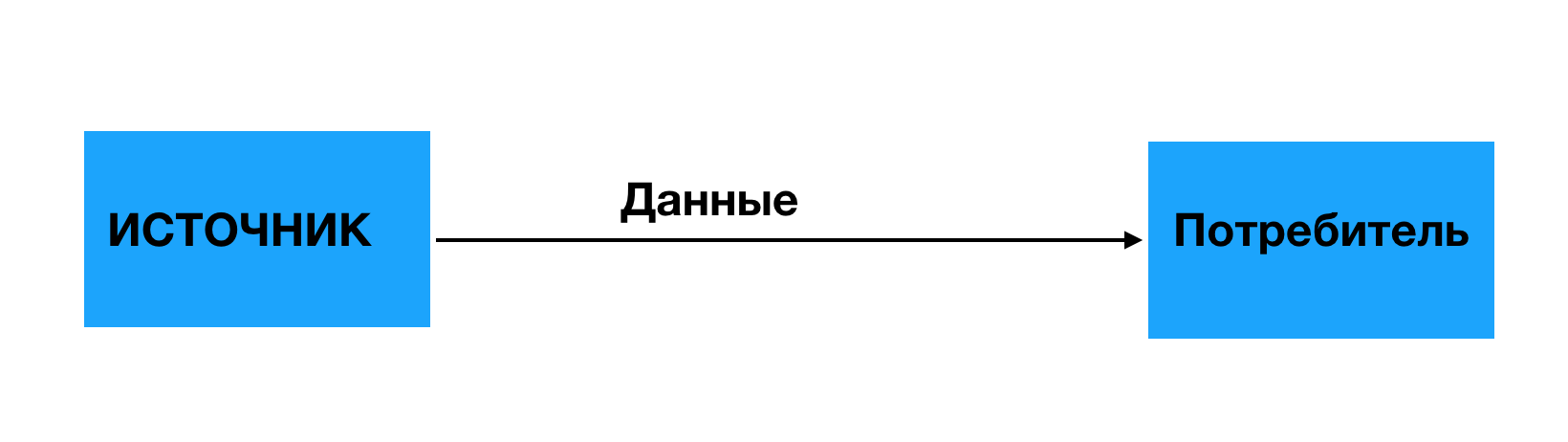
С другой стороны, в реальных проектах современного мира все выглядит немного по-другому. Примерно вот так:
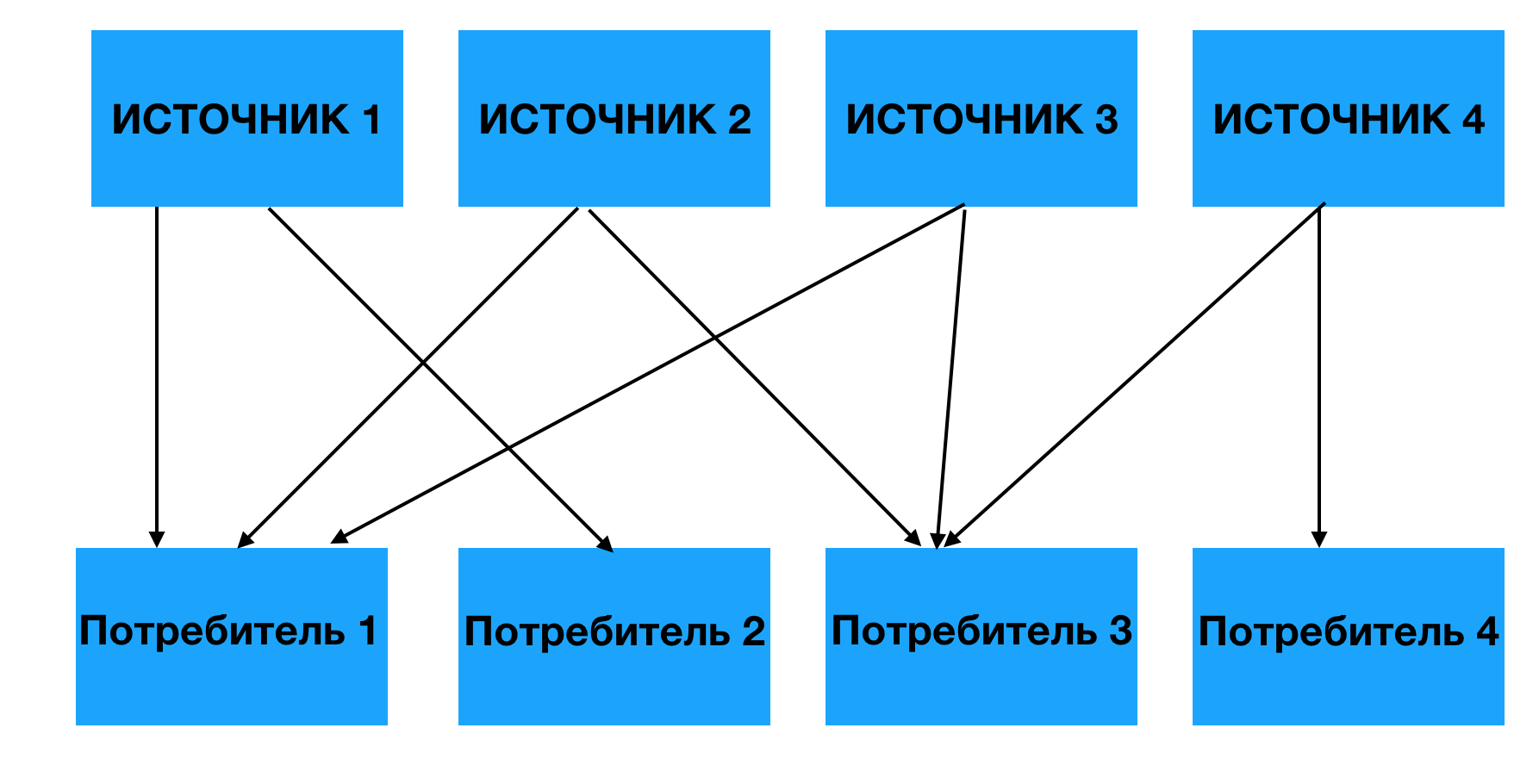
Получается, имея 4 источника и 4 системы потребителя, нужно написать 16 интеграций. Apache Kafka – решает эту проблему, агрегирую внутри себя сообщения от источников, которые потом прочитываются потребителями.
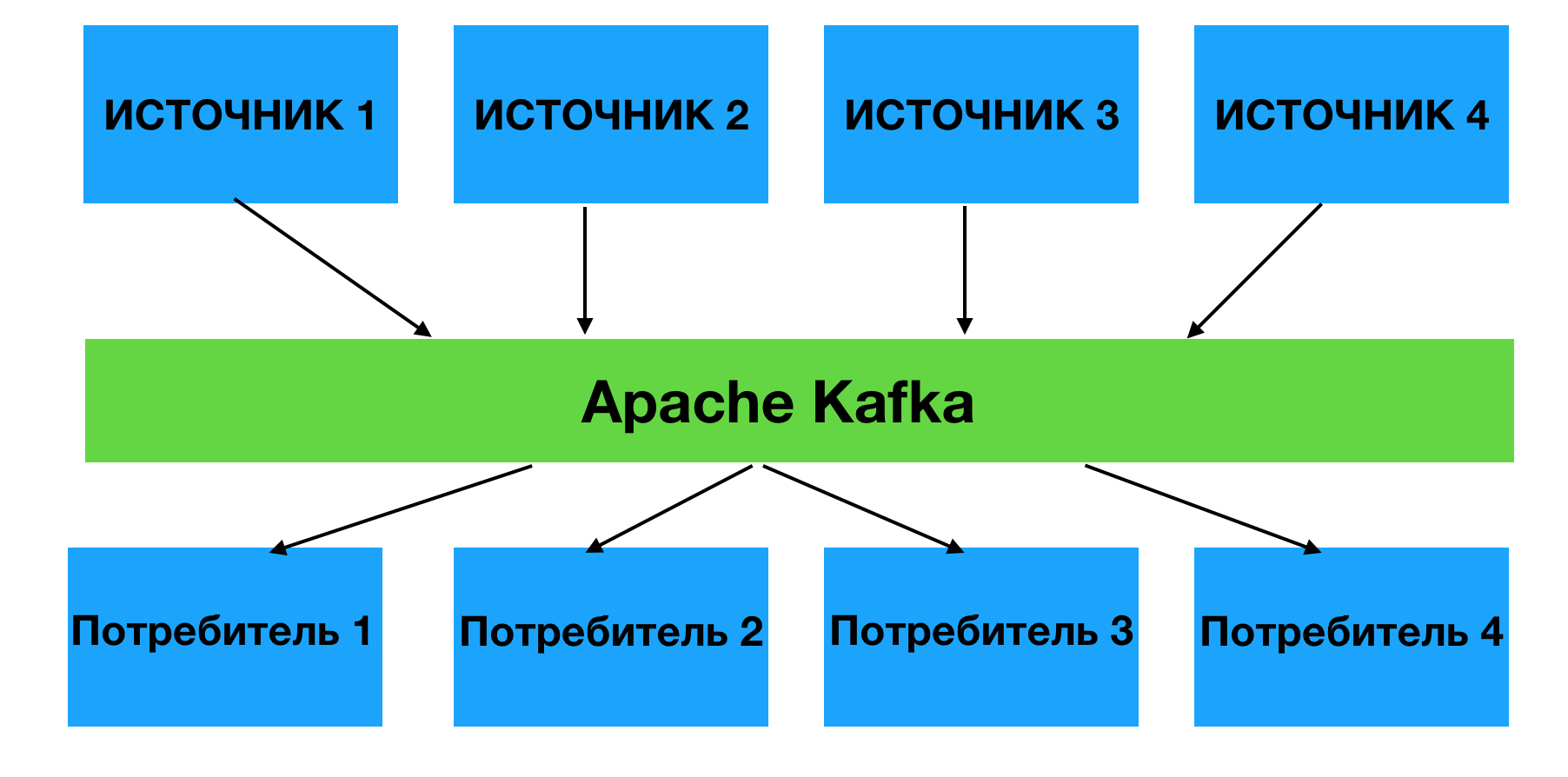
Детально о том как устроена Kafka поговорим как-нибудь в другой раз, а сейчас давайте перейдем к практике и за 5 минут развернем “Кафку” у себя на MacOS.
Всего необходимо сделать следующие шаги:
- Установить brew
- Скачать и установить Java 8 JDK
- Скачать и разархивировать Apache Kafka
- Установить Kafka с помощью brew
- Настроить конфигурационные файлы Zookeeper и Kafka
- Запустить Zookeeper и Kafka
- Создать Topic
- Запустить потребителя и поставщика данных и отправить сообщения в Kafka
Поехали!
1. Чтобы установить brew просто введите эту строку в терминале
|
1 |
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" |
2. Для установки java 8 используем brew. Введите последовательно 2 команды. Сначала
|
1 |
brew tap caskroom/versions |
Она будет выполняться около 1 минуты, затем следующую
|
1 |
brew cask install java8 |
Проверить, что установка прошла успешно можно командой
|
1 |
java -version |
Вывод должен быть таким

3. Переходим на сайт https://kafka.apache.org/downloads и скачиваем бинарник.
После успешной загрузки необходимо разархивировать Kafka.
4. Устанавливаем Kafka так же с помощью brew командой
|
1 |
brew install kafka |
5. Далее необходимо настроить конфигурацию Zookeeper и Kafka.
Zookeeper – что-то типо аркистратора для Kafka. Без Zookeeper вы не сможете запустить Kafka.
Создаем папку data в разархивированном архиве Kafka. Внутри нее создаем еще две папки Kafka и Zookeeper. Далее редактирует два файла: zookeeper.properties и server.properties. Создаём папки с помощью последовательного выполнения команд в терминале
|
1 2 3 4 |
cd kafka_2.12-2.0.0 mkdir data mkdir data/zookeper mkdir data/kafka |
После выполнения этих команд в том же терминале можете убедиться что папки создались (командой ls)
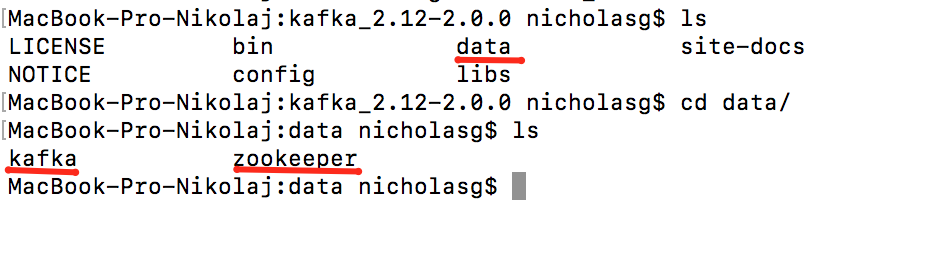
Далее, редактируем файлы zookeeper.properties и server.properties. Здесь нам потребуется получить полный адрес созданной ранее папки zookeeper. Для этого вводим команды
|
1 2 |
cd data/zookeeper pwd |
Полученный путь нужно скопировать.

Теперь нам необходимо вернуться в родительский каталог для Kafka и отредактировать конфигурационный файл с помощью nano
|
1 |
nano ../../config/zookeeper.properties |
Находим dataDir и вставляем вместо временного пути наш. Нажимаем ctrl+X и выходим в терминал, сохраняя изменения.
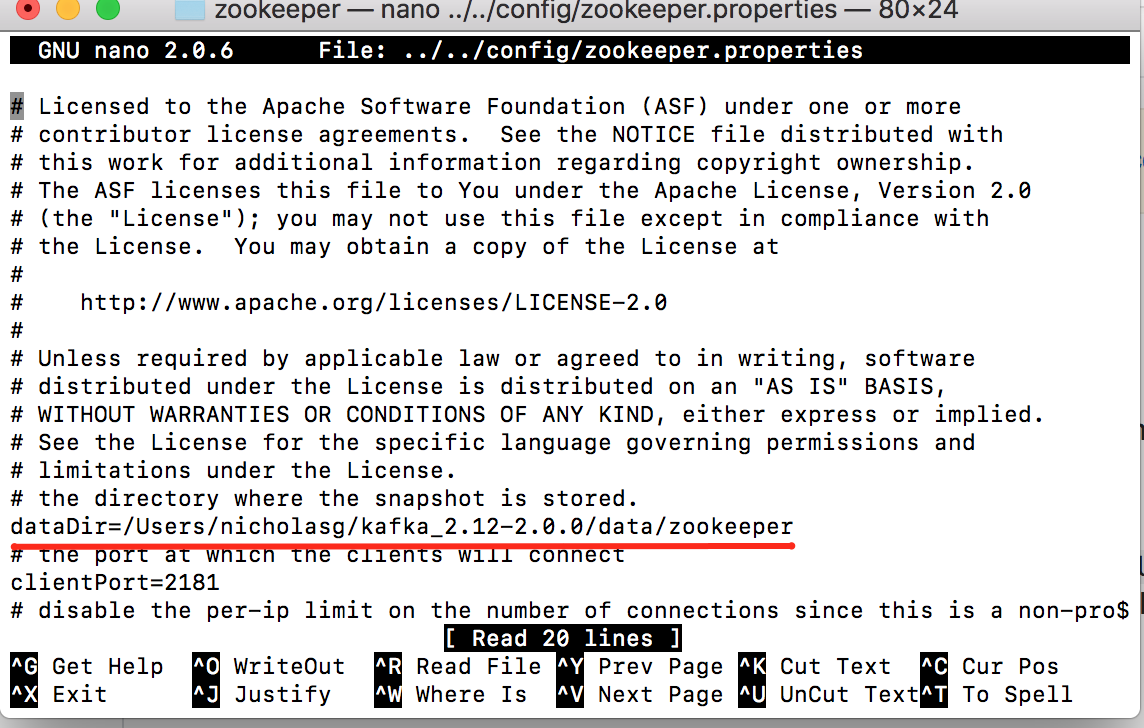
Повторяем операцию для server.properties.
|
1 2 |
cd data/kafka pwd |

Копируем путь до папки и открываем файл server.properties с помощью nano и в log.dirs вставляем полный путь до папки data/kafka, после – сохраняем.
|
1 |
nano ../../config/server.properties |
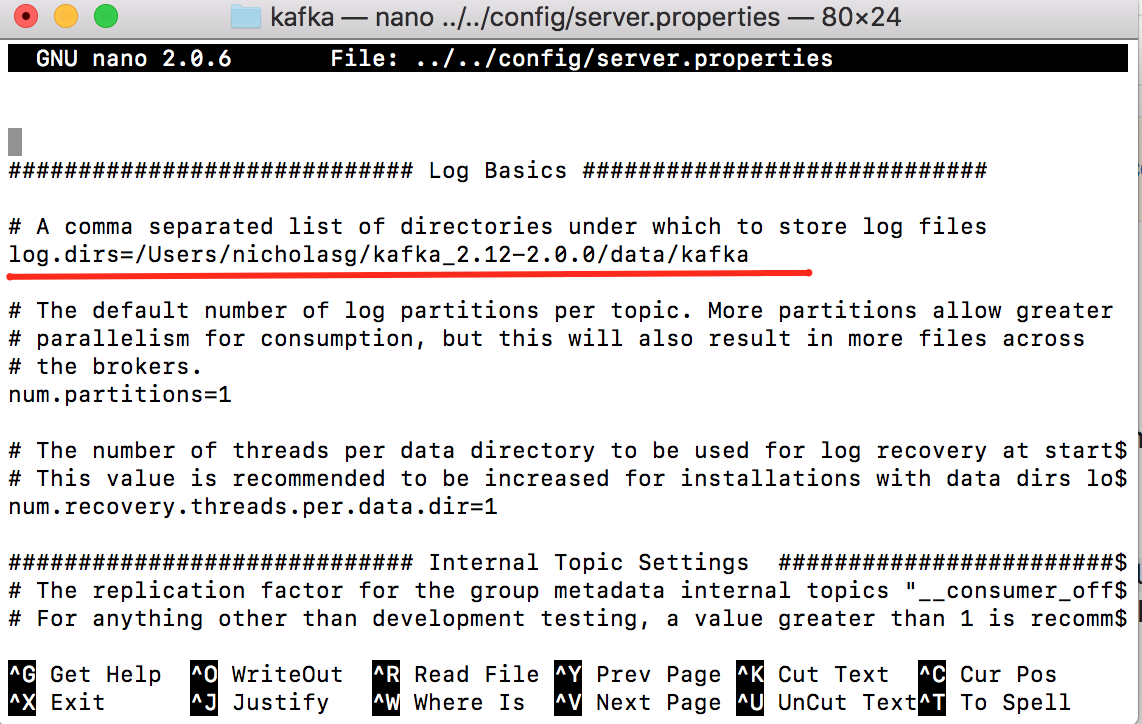
6. Отлично! Подготовительная работа позади, и мы можем запустить Zookeeper и Kafka. Делать это нужно последовательно в двух разных терминалах следующими командами
|
1 |
zookeeper-server-start config/zookeeper.properties |
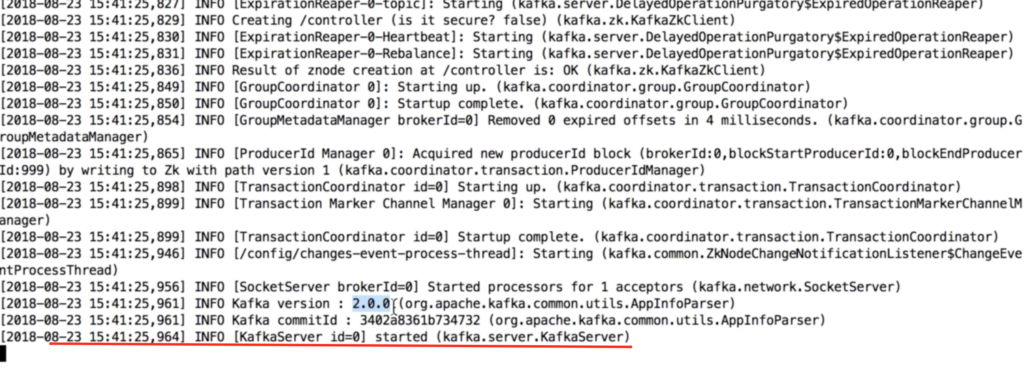
Успешным выполнением первой команды будет следующий лог в терминале

Далее открываем второй терминал и выполняем вторую команду
|
1 |
kafka-server-start config/server.properties |
Успешным выполнением будет лог
7. Не закрывая терминалы с запущенными Zookeeper и Kafka, открываем новый и пишем команду, которая создает топик. Топик (Topic) – это непосредственно место, куда будут записываться сообщения и откуда они будут считываться. Топик состоит из сегментов (Partitions), сегменты включают в себя очередь сообщений, которые имеют возрастающий целочисленный id (offsets). В терминале прописываем следующую команду
|
1 |
kafka-topics --zookeeper 127.0.0.1:2181 --topic first_topic --create --partitions 3 --replication-factor 1 |
параметр replication-factor – это одна из важных фичей Kafka. Указывает сколько копий содержимого данного топика будет реплецироваться с одного брокера на другого в рамках кластера Kafka. Рекомендуемое значение > 1. В нашем примере 1, потому что у нас всего один брокер.
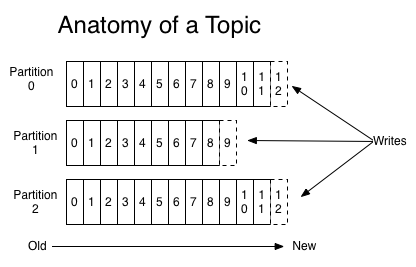
8. Осталось запустить поставщика и потребителя данных. Воспользуемся Bootstrap-servers, предоставляемыми вместе с Kafka. И так, не закрывая открытые консоли для Zookeeper и Kafka, открываем еще два терминала. В одном пишем команду
|
1 |
kafka-console-consumer --bootstrap-server 127.0.0.1:9092 --topic first_topic |
После ввода этой команды вы ничего не увидите. Не переживайте, все нормально, так как данных для получения из топика еще нет. Теперь, во втором терминале пишем следующую команду
|
1 |
kafka-console-producer --broker-list 127.0.0.1:9092 --topic first_topic |
После ввода команды, прямо в консоли пишите любые сообщения и смотрите, что происходит. Вы передаете данные в топик из которого, потребитель сразу читает данные и выводит на свою консоль.

Вот так мы с вами за 5 минут и 8 шагов сумели передать первые сообщения через Apache Kafka!





2 comments On Apache Kafka. Быстрый старт на MacOS
MacBook-Pro-Roman:kafka_2.12-2.1.0 roman$ kafka-console-consumer –bootstrap-server 127.0.0.1:9092 –topic first_topic
Даров, колян!
Аварийская нация самая аварийская нация на свете среди аварийских наций
ПОЛУЧИЛОСЬ! СПАСИБО!
Молодец!