Отойдем от классической последовательности описания чего-либо. Вместо определения мы начнем с разницы. Разницы между стеком и обычным, классическим массивом, и только после дадим определение структуре данных как стек.
Ранее мы рассматривали алгоритмы сортировки, используя за основу массив. Почему? Массивы отлично подходят для описания, если можно так сказать, реляционной структуры. Используя их мы можем получить доступ к любому элементу по индексу, записать элемент в массив, изменить, сортировать, удалять элементы. Поэтому такие массивоподобные структуры данных (списки, деревья, графы, связные списки и т.д.) отлично подходят для задач, где такого рода операции выполняются часто. Это может быть база данных сотрудников или склада помидоров. Задачи, в которых нам необходим функционал массивов. Структура данных стек (хотя то что будет написано далее справедливо и для очередей, и приоритетных очередей) используется разработчиками чаще как внутренний инструмент, облегчающий написания самой программы и ее алгоритмов. Другими словами, массив – работает со внешними данными, стек – для особенных манипуляций с этими данными. В общем стек – другой уровень абстракции. За счет чего для реализации некоторых алгоритмов он предпочтительнее массива? Благодаря ограничениям, которые накладываются на стек для работы с данными, мы получаем отличный инструмент для решения задач определенного вида.
Теперь наконец дадим определение. Стек – структура данных, основанная на массиве, реализующая парадигму работы с данными по принципу FIFO (First In First Out – первый вошел, первый вышел). Эта парадигма накладывает на стек ограничения работы с данными: доступ только к элементу лежащему на вершине стека, вставка и извлечение элемента только с вершины. Используя стек мы имеем доступ только к ОДНОМУ элементу. Для того чтобы извлечь из стека элемент со дна, необходимо извлечь все элементы.
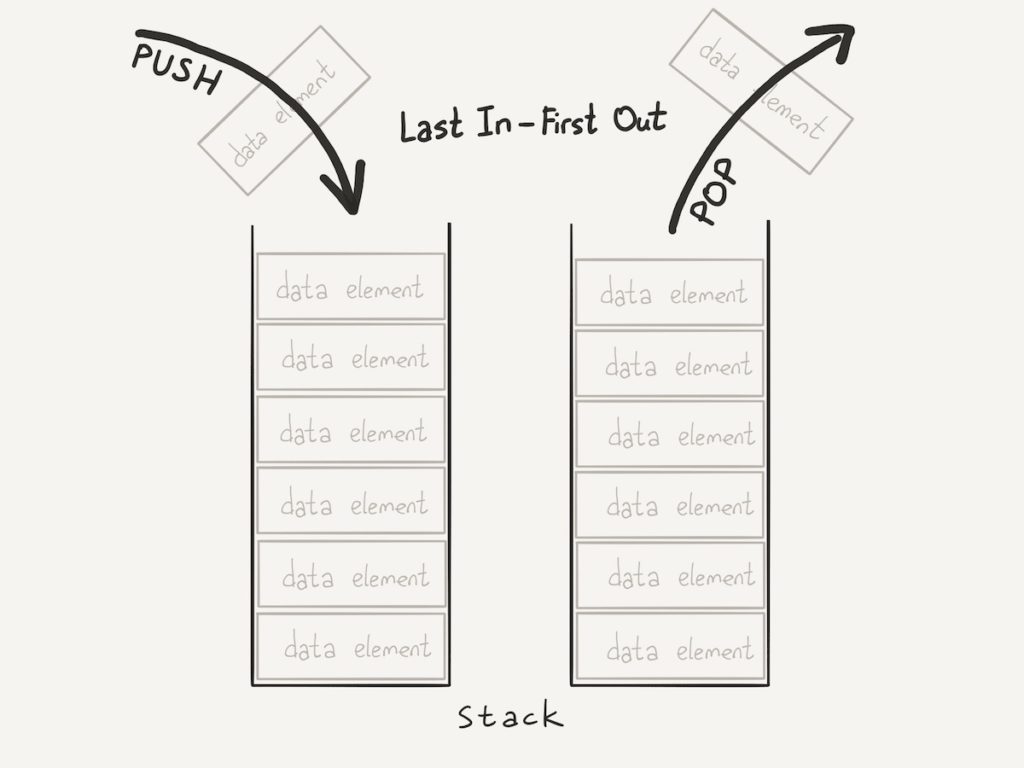
Реализуем стек целых чисел с помощью средств языка Java.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
public class Stack { private int size; // Размер стека private int top; // индекс вершины private int[] stack; // сам стек public Stack(int size) { // конструктов this.size = size; top = -1; // -1 потому что стек пуст stack = new int[size]; // иницилизазция } public int pop() { // извлечение элемента return stack[top--]; } public int peek() { // получение элемента return stack[top]; } public void push(int a) { // вставка элемента stack[++top] = a; } public boolean isEmpty() { // проверка путой ли стек return (top == -1); } public boolean isFull() { // проверка полон ли стек return (top == size - 1); } public static void main(String[] args) { Stack stack = new Stack(5); stack.push(1); stack.push(2); stack.push(3); stack.push(4); stack.push(5); while (!stack.isEmpty()) { System.out.print(stack.pop() + " "); } } } |
Вывод:
|
1 |
5 4 3 2 1 |
Мы описали классический функционал стека. Однако, вы спросите: кто должен обрабатывать ошибки, связанные с переполнением стека или наоборот запросом элемента из пустого стека? Единого ответа нет, мы в нашем примере оставляем необходимость проверки пользователю класса и предоставляем соотвествующие методы. Продемонстрируем работу стека на простом примере.
Задача “Поиск парных скобок”
Необходимо написать программу, которая будет проверять правильность записи различных скобок в строке. Каждая открывающаяся скобка должна иметь свою закрывающуюся, причем в правильном порядке согласно правилам синтаксиса языка джава.
с(в) – правильно.
с(р{ – неправильно
{([s])} – правильно.
Для решения задачи воспользуемся стеком, состоящим из элементов типа char. Каждый раз проходя по введенной строке мы будем складывать в стек открывающуюся скобку, далее встречая соответствующую ей закрывающуюся скобку – извлекать. При корректно введенной строке стек будет пустым, потому что на каждую открытую скобку будет своя закрытая.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
import java.util.Scanner; public class BracketChecker { String str; public BracketChecker(String str) { this.str = str; } public void check() { int size = str.length(); Stack stack = new Stack(size); for (int i = 0; i < size; i++) { char ch = str.charAt(i); switch (ch) { case '{': case '[': case '(': stack.push(ch); break; case '}': case ']': case ')': if (!stack.isEmpty()) { char chx = stack.pop(); if ((ch == '}' && chx != '{') || (ch == ']' && chx != '[') || (ch == ')' && chx != '(')) { System.out.println("Error " + ch + " at " + i); } } else System.out.println("Error " + ch + " at " + i); break; default: break; } } if (!stack.isEmpty()) System.out.println("Error: missing right delimiter"); } public static void main(String[] args) { Scanner scanner = new Scanner(System.in); String str = scanner.nextLine(); BracketChecker bracketChecker = new BracketChecker(str); bracketChecker.check(); } } |
Ввод
|
1 |
[([)}] |
Вывод
|
1 2 |
Error ) at 3 Error } at 4 |
Как вы видите, мы успешно использовали стек для реализации данного алгоритма. Можно было бы использовать и массив, однако стек более предпочтительный вариант.
Эффективность стеков
Реализованный нами стек позволяет извлекать и вставлять элементы за время O(1), т.е. независимо от размеров стека.




