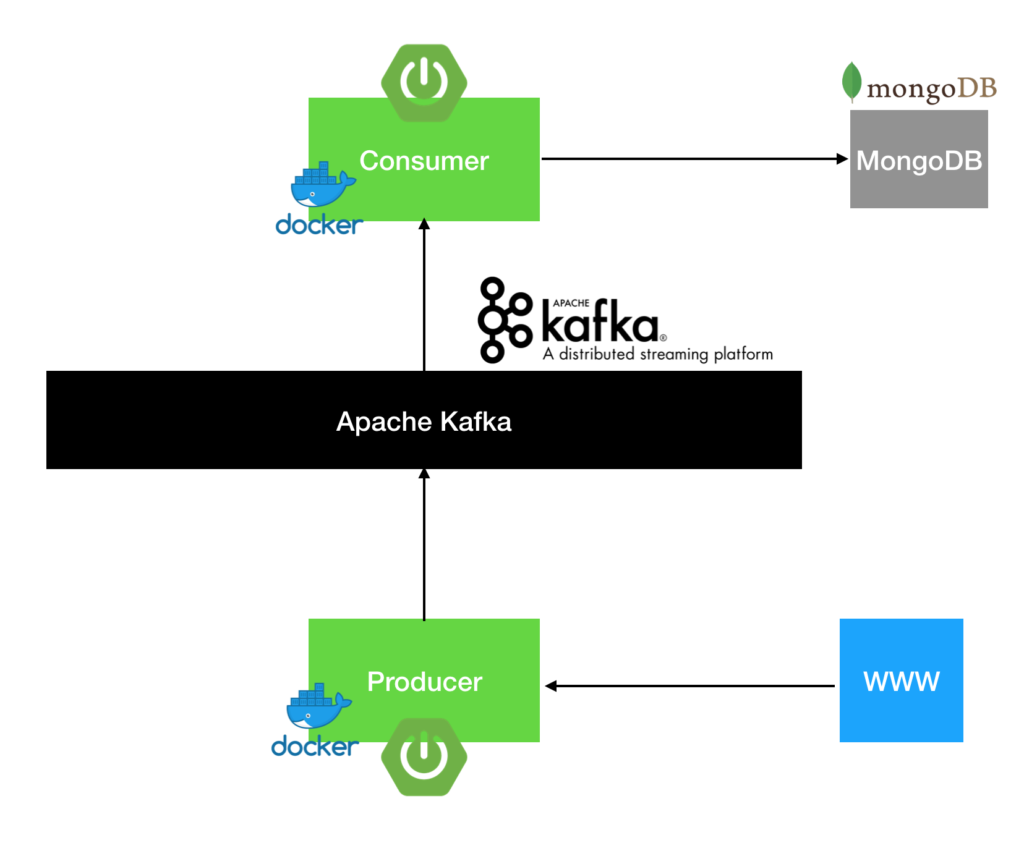
Сегодня мы приготовим два микросервиса на Spring Boot и развернем их в Docker. Про то что такое Docker написано здесь. Один микросервис будет отвечать за получение данных из вне и записывать их в нужном виде в Kafka. Про то как локально настроить у себя на компьютере Apache Kafka написано здесь. Второй микросервис будет считывать данные из Kafka и сохранять их в MongoDB.
MongoDB – это NoSQL база данных, поддерживающая реактивную модель программирования, рассчитана на большое количество insert-ов. Структура хранения данных в MongoDB – BJSON – бинарный JSON. База является документоориентированной т.е. запись в базе это json документ с данными.
На этом превью можно заканчивать и начинать создавать микросервисы.
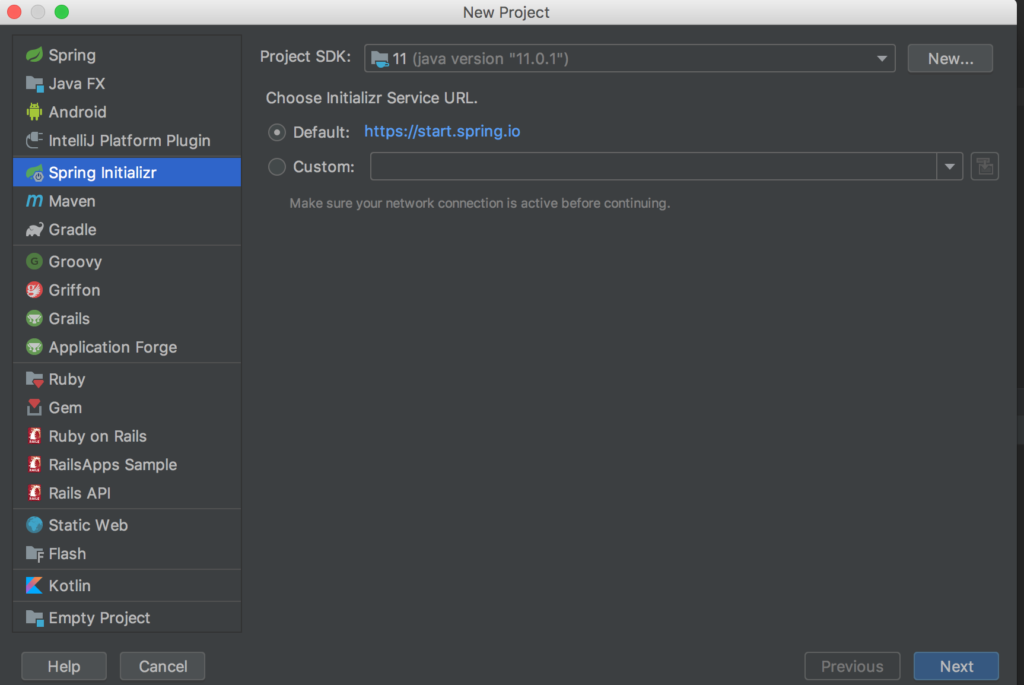
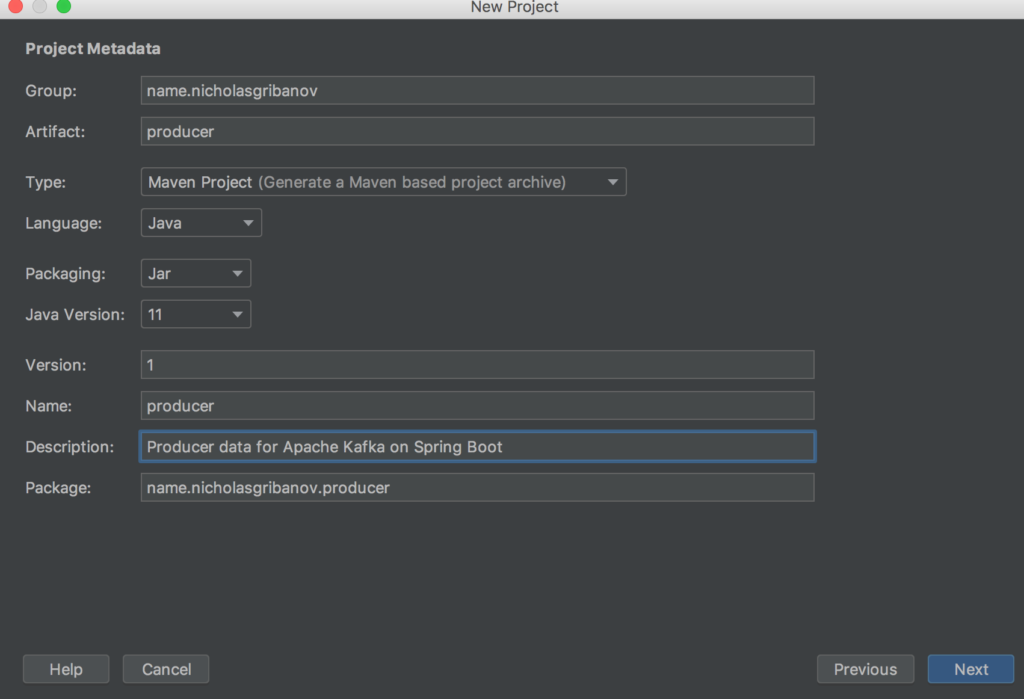
Начнем с нижнего уровня и создадим микросервис для записи данных. Для начала нам необходимо создать 3 отдельных проекта для нашей архитектуры. Два проекта – микросервисы producer и consumer, еще один проект будет содержать общие классы для двух микросервисов. Так сделано для удобства обновления, а так же для корректной работы собственноручно организованной сериализации. Об этом ниже. Создаем три проекта со следующими опциями:
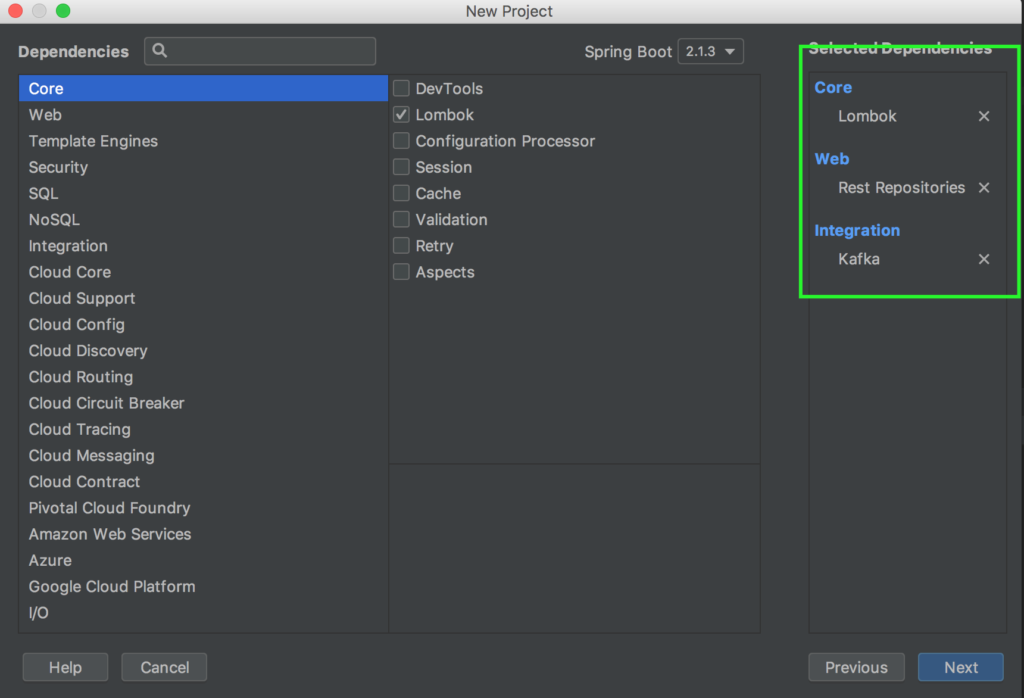
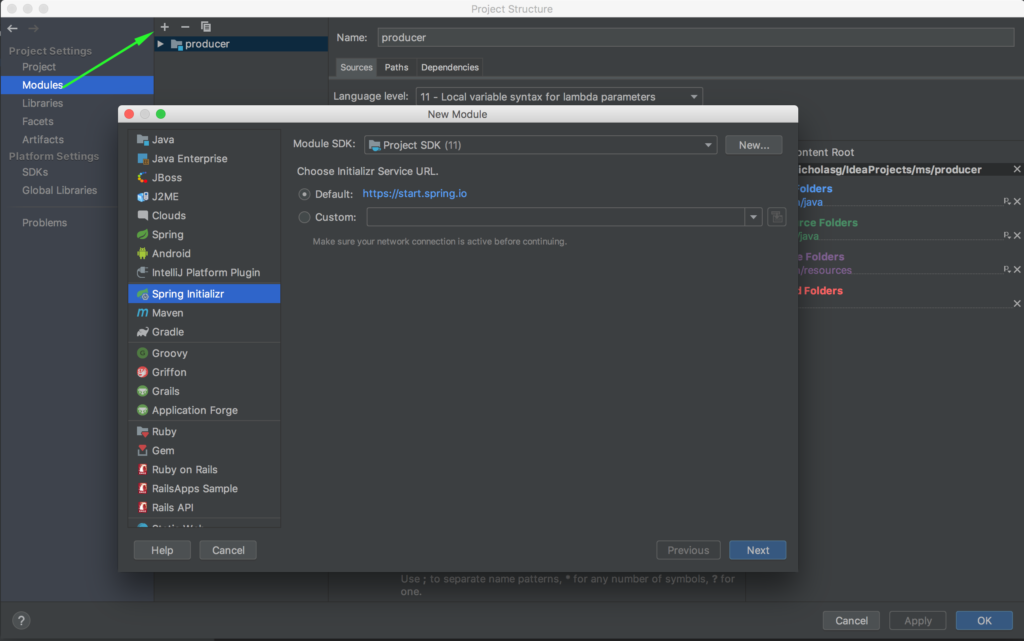

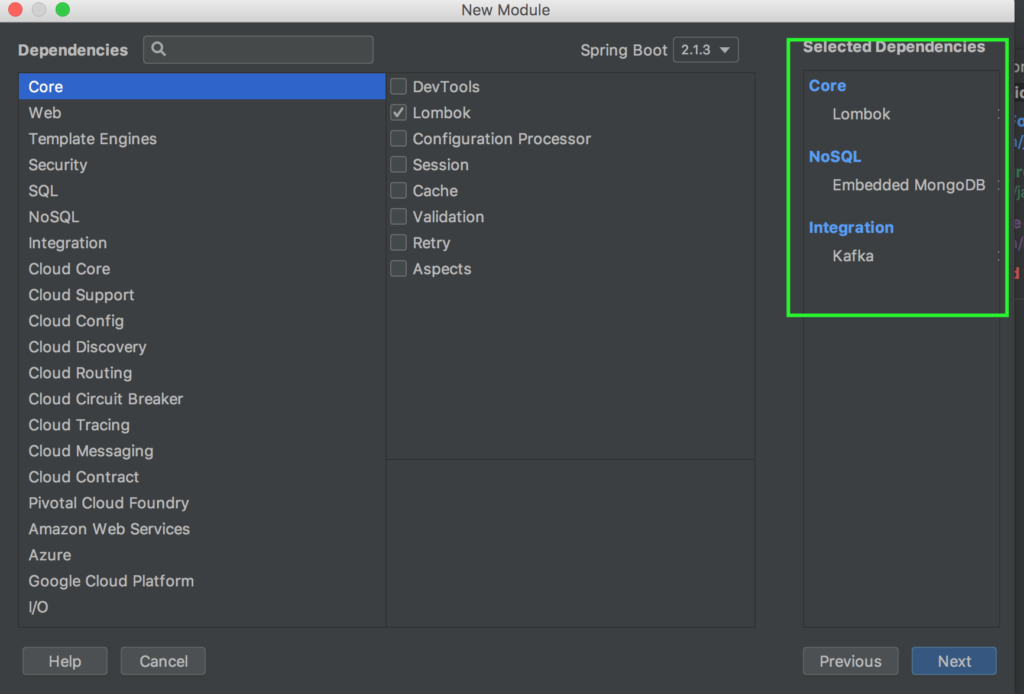
В результате мы должны получить следующую структуру проекта:
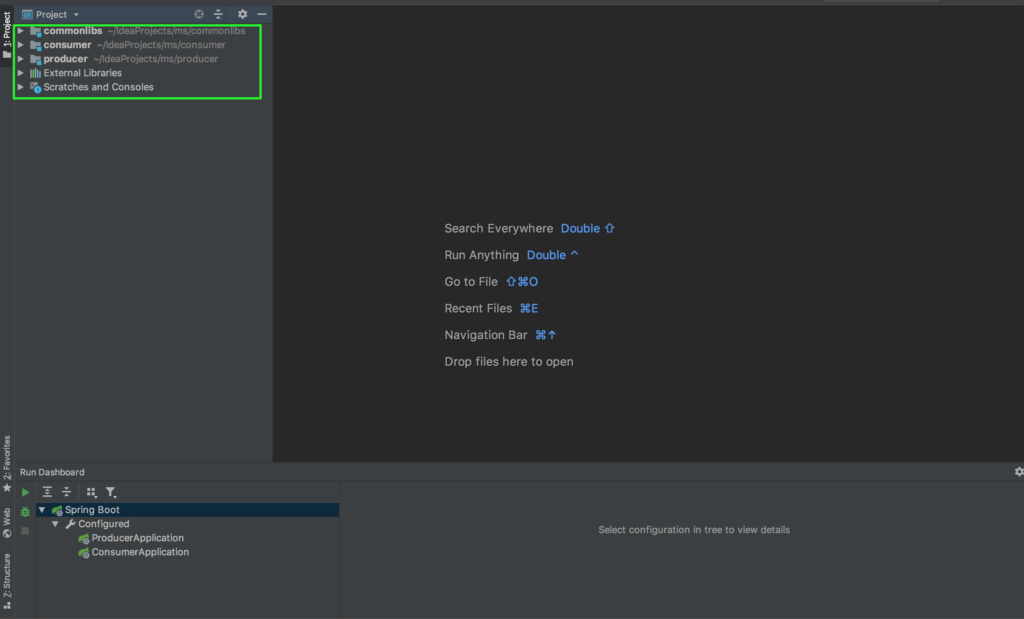
Данные мы будем получать с помощью rest-клиента, после, полученные данные передавать в Kafka. Для начала создадим RestTemplate для получения данных. Для этого нам понадобиться создать конфигурацию и сервисы для получения данных.
|
1 2 3 4 5 6 7 8 9 10 |
//RestClient.java @Configuration public class RestClientConfig { @Bean public RestTemplate restTemplate(RestTemplateBuilder builder) { return builder.build(); } } |
Далее необходимо в проекте common-libs создать DTO (Data Transfer Object) – это объект, который мы будем передавать из одного микросервиса в Kafka и другим читать. Воспользуемся для этого одним интересным приемом. Для начало вам понадобиться скачать и установить приложение Postman. Запустив, мы отправляем запрос “http://apifaketory.com/api/user?limit=3” сервер с которого будем получать данные.
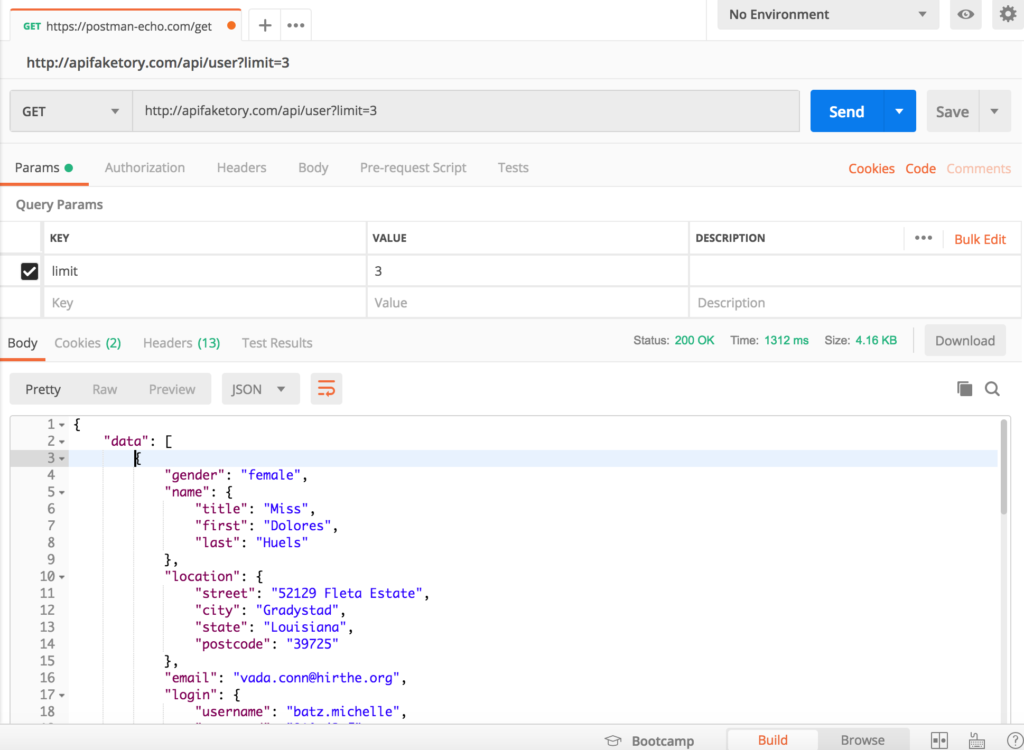
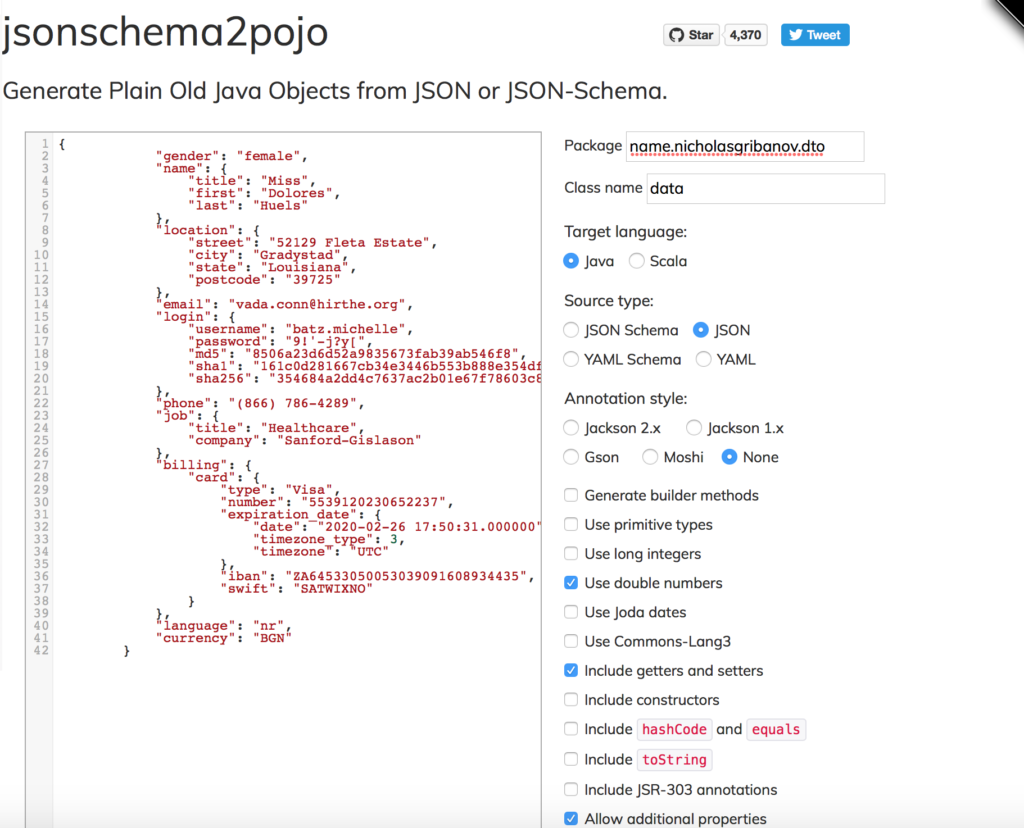
Если все сделано правильно, то в секции body вы получите json файл с данными. Далее, необходимо создать java-классы для байндинга этого json в объекты. Для этого воспользуемся ресурсом http://www.jsonschema2pojo.org. Скопируйте один json объект из ответа postman, вставьте в левую часть как показано на рисунке и сделайте необходимые настройки. ОБЯЗАТЕЛЬНО сделайте классы сериализуемыми!!! После скачиваем архив с уже готовыми классами и добавляем в проект common-libs.
Дополнительно добавляем класс UserData следующего содержания:
|
1 2 3 4 5 6 7 8 9 10 11 |
public class UserData { private List<Data> data = new ArrayList<>(); public List<Data> getData() { return data; } public void setData(List<Data> data) { this.data = data; } } |
После необходимо добавить в pom следующую запись:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>11</source> <target>11</target> </configuration> </plugin> </plugins> </build> |
И нажать install. Это даст нам возможность подключить зависимость common-libs в наши микросервисы.
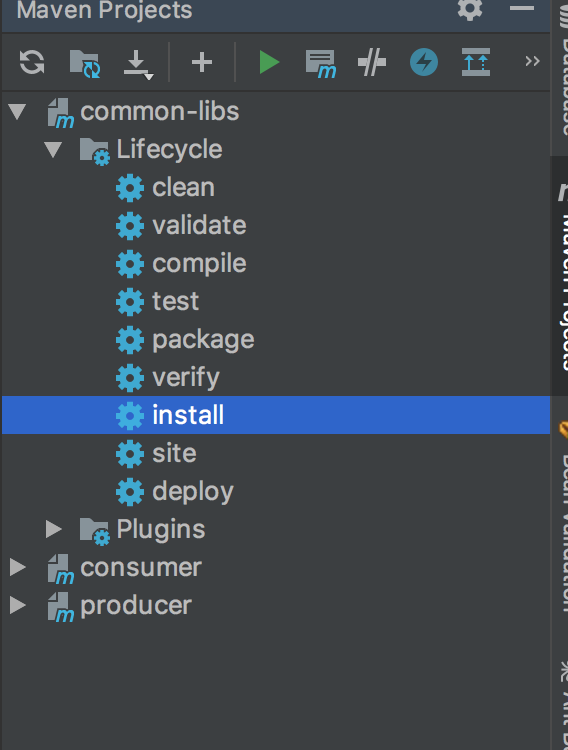
Продолжим написание producer. Добавляем зависимость а pom и настирываем получение данных с помощью RestTemplate.
|
1 2 3 4 5 |
<dependency> <groupId>name.nicholasgribanov</groupId> <artifactId>common-libs</artifactId> <version>1</version> </dependency> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
//ApiService.java public interface ApiService { List<Data> getData(Integer limit); } //ApiServiceImpl.java @Service public class ApiServiceImpl implements ApiService { private RestTemplate restTemplate; private String apiUrl; public ApiServiceImpl(RestTemplate restTemplate, @Value("${api_url}")String apiUrl) { this.restTemplate = restTemplate; this.apiUrl = apiUrl; } @Override public List<Data> getData(Integer limit) { UriComponentsBuilder builder = UriComponentsBuilder .fromUriString(apiUrl) .queryParam("limit", limit); UserData data = restTemplate.getForObject(builder.toUriString(), UserData.class); return data.getData(); } } |
Теперь перейдем к конфигурации Kafka. Создадим три класса: в одном сделаем конфигурацию самой Kafka, во втором конфигурацию топиков и в третьем опишем сам процесс записи данных в Kafka.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
//KafkaProducerConfig.java @Configuration public class KafkaProducerConfig { @Value("${kafka.bootstrapAddress}") private String bootstrapAddress; @Bean public ProducerFactory<String, Data> producerFactory() { Map<String, Object> config = new HashMap<>(); config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress); config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); return new DefaultKafkaProducerFactory<>(config); } @Bean public KafkaTemplate<String, Data> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); } } //KafkaTopicConfig.java @Configuration public class KafkaTopicConfig { @Value(value = "${kafka.bootstrapAddress}") private String bootstrapAddress; @Value(value = "${kafka.topic.name}") private String topicName; @Bean public KafkaAdmin kafkaAdmin() { Map<String, Object> config = new HashMap<>(); config.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress); return new KafkaAdmin(config); } @Bean public NewTopic topic() { return new NewTopic(topicName, 1, (short) 1); } } //MessageProducer.java @Slf4j @NoArgsConstructor @Component public class MessageProducer { @Autowired private KafkaTemplate<String, Data> kafkaTemplate; @Value(value = "${kafka.topic.name}") private String topicName; public void sendMessage(Data data) { ListenableFuture<SendResult<String, Data>> future = kafkaTemplate.send(topicName, data); future.addCallback(new ListenableFutureCallback<SendResult<String, Data>>() { @Override public void onFailure(Throwable throwable) { log.error("Unable to send message = {} dut to: {}", data, throwable.getMessage()); } @Override public void onSuccess(SendResult<String, Data> stringDataSendResult) { log.info("Sent Message = {} with offset = {}", data, stringDataSendResult.getRecordMetadata().offset()); } }); } } |
Файл application.properties должен выглядеть так:
|
1 2 3 |
api_url=http://apifaketory.com/api/user?limit= kafka.bootstrapAddress=127.0.0.1:9092 kafka.topic.name=topic1 |
Отлично! Проверим как работает наша запись в Kafka. Проверьте, что Kafka запущена на вашем компьютере! Далее допишем отправку сообщений в Kafka в нашем главном классе и запустим.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
@EnableScheduling @SpringBootApplication public class ProducerApplication { public static void main(String[] args) { ApplicationContext context = SpringApplication.run(ProducerApplication.class, args); MessageProducer producer = context.getBean(MessageProducer.class); ApiService service = context.getBean(ApiServiceImpl.class); service.getData(3).forEach(producer::sendMessage); } } |
Если вы все сделали правильно, то в логах у вас будет сообщение о том, что данные передались! Теперь упакуем наш сервис в Docker Image и запустим его внутри Docker – контейнера. Для этого нам необходимо собрать “толстый” джарник нашего приложения (так же нажать install, как в случае с commom-libs) и написать Dockerfile в корне проекта со следующим содержанием:
|
1 2 3 4 5 6 7 8 |
FROM centos RUN yum install -y java VOLUME /tmp ADD /target/producer-1.jar myapp.jar RUN sh -c 'touch /myapp.jar' ENTRYPOINT ["java", "-Djava.security.egd=file:/dev/./urandom","-jar","/myapp.jar"] |
Далее необходимо проверить, что во всех ваших pom-файлах указано, что версия языка используется 8, несмотря на то что мы при старте проекта использовали Java 11. Для запуска в контейнере нам нужна именно Java 8.
|
1 2 3 |
<properties> <java.version>1.8</java.version> </properties> |
Для common-libs так же нужно изменить конфигурацию плагина:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> |
После того как вы создадите Dockerfile, IntelliJ IDEA предложит вам установить плагин для работы с Docker. Воспользуйтесь этой возможностью, очень удобный инструмент. Теперь нам необходимо изменить конфигурацию нашей локальной Kafka, потому что теперь подключение к Kafka будет осуществляться из Docker-контейнера. Необходимо прописать ip – адрес в файл server.properties, а так же обновить конфигурационные файл в producer. IP-адрес можно узнать через консоль командой ipconfig для windows и netstat -rn для unix-систем. В файле server.properties, находим следующую строчку и прописываем ей свой ip – адрес.
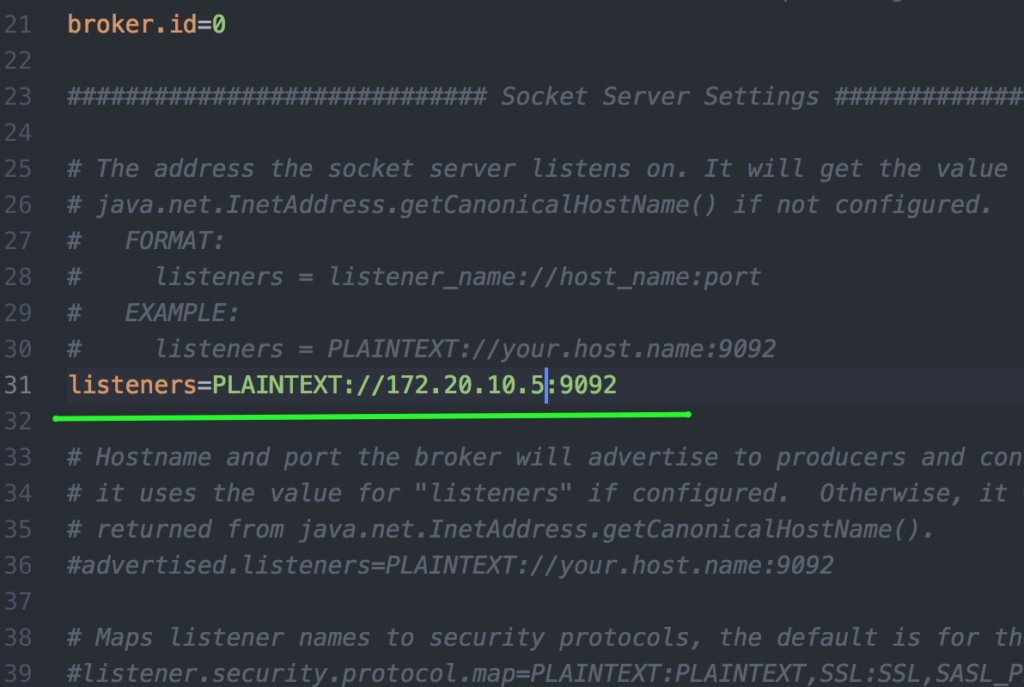
Отлично, теперь собираем проект producer с помощью команды maven:install, настраиваем создание Docker Image и запуск контейнера либо через Intellij IDEA, либо командой:
|
1 |
docker build -t producer-img . && docker run -p 9090:9092 --name producer producer-img |
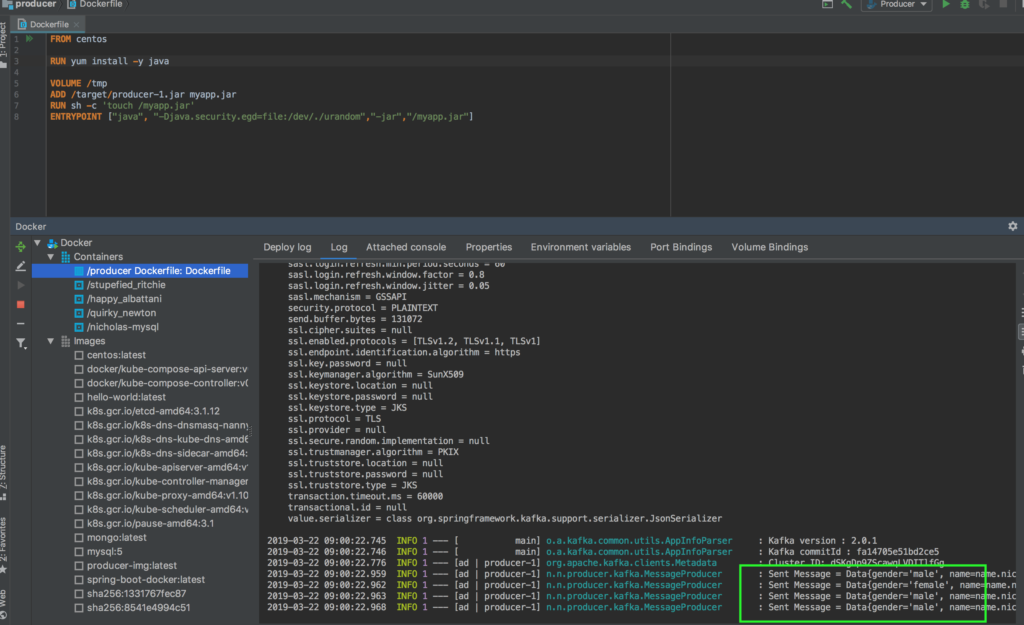
Если все сделано правильно, то в логах контейнера можно увидеть, что мы записали сообщения в Kafka с из Docker контейнера!
Отлично! Мы написали наш первый микросервис и развернули его в Docker контейнере. Приступим к написанию второго микросервиса, потребителя (consumer) данных из Apache Kafka и записи в MongoDB. Для начала необходимо так же настроить Kafka.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
//KafkaConsumerConfig.java @EnableKafka @Configuration public class KafkaConsumerConfig { @Value(value = "${kafka.bootstrapAddress}") private String bootstrapAddress; public ConsumerFactory<String, Data> consumerFactory() { Map<String, Object> config = new HashMap<>(); config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress); config.put(ConsumerConfig.GROUP_ID_CONFIG, "consuming"); DefaultJackson2JavaTypeMapper typeMapper = new DefaultJackson2JavaTypeMapper(); Map<String, Class<?>> classMap = new HashMap<>(); classMap.put("name.nicholasgribanov.dto.Data", Data.class); typeMapper.setIdClassMapping(classMap); typeMapper.addTrustedPackages("*"); JsonDeserializer<Data> jsonDeserializer = new JsonDeserializer<>(Data.class); jsonDeserializer.setTypeMapper(typeMapper); jsonDeserializer.setUseTypeMapperForKey(true); return new DefaultKafkaConsumerFactory<>(config, new StringDeserializer(), jsonDeserializer); } @Bean public ConcurrentKafkaListenerContainerFactory<String, Data> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, Data> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); return factory; } } //KafkaTopicConfig.java @Configuration public class KafkaTopicConfig { @Value(value = "${kafka.bootstrapAddress}") private String bootstrapAddress; @Value(value = "${kafka.topic.name}") private String topicName; @Bean public KafkaAdmin kafkaAdmin() { Map<String, Object> config = new HashMap<>(); config.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress); return new KafkaAdmin(config); } @Bean public NewTopic topic() { return new NewTopic(topicName, 1, (short) 1); } } //MessageListener.java public class MessageListener { @Autowired private DataService dataService; @KafkaListener(topics = "${kafka.topic.name}", containerFactory = "kafkaListenerContainerFactory") public void listener(Data data) { System.out.println("Recieved message: " + data); dataService.saveMessage(data); } } |
Далее, создаем репозиторий для записи данных в MongoDB, а так же сервис для выполнения операций над MongoDB. Необходимо добавить несколько дополнительных зависимостей, а так же удалить блок <scope> у внутренней MongoDB. В pom.xml добавляем следующие зависимости:
|
1 2 3 4 5 6 7 8 9 |
<dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.9.8</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-mongodb</artifactId> </dependency> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
//DataRepository.java @Repository public interface DataRepository extends CrudRepository<Data, String> { } //DataService.java public interface DataService { Data saveMessage(Data data); } //DataServiceImpl.java @Service public class DataServiceImpl implements DataService { private DataRepository repository; public DataServiceImpl(DataRepository repository) { this.repository = repository; } @Override public Data saveMessage(Data data) { return repository.save(data); } } |
Осталось только запустить приложение потребителя, считать данные из Kafka и сохранить их в MongoDB.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@SpringBootApplication public class ConsumerApplication { public static void main(String[] args) { SpringApplication.run(ConsumerApplication.class, args); } @Bean public MessageListener messageListener() { return new MessageListener(); } } |
Файл application.properties для consumer:
|
1 2 3 4 5 |
kafka.bootstrapAddress=172.20.10.5:9092 kafka.topic.name=topic2 spring.data.mongodb.port=0 spring.data.mongodb.host=localhost |
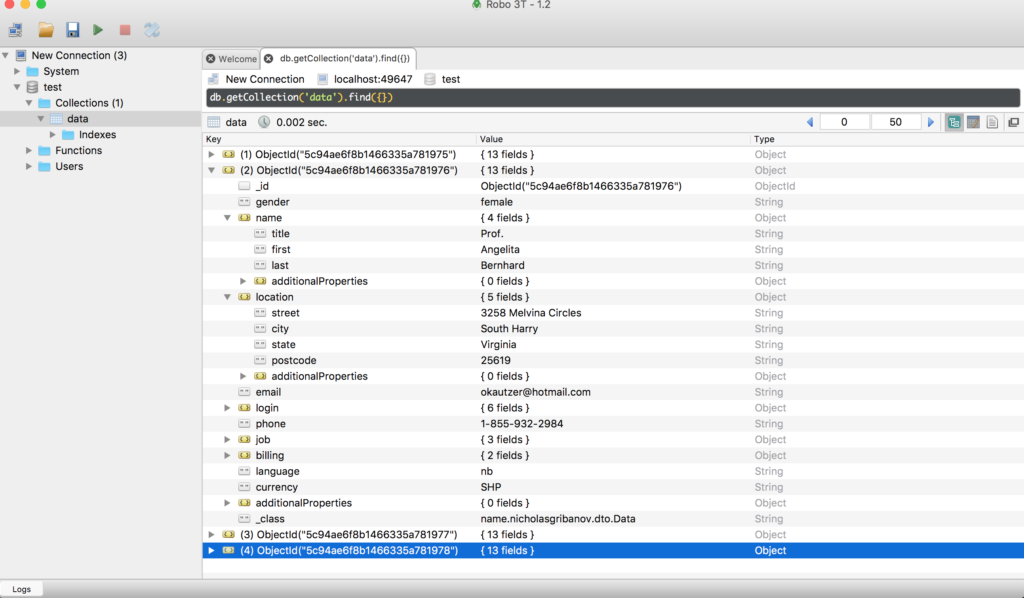
Если вы все сделали правильно, то вы увидите сообщения, что объекты получены, а так же с помощью программы Robo3T можете посмотреть, что объекты реально записались в базу данных. Порт, к которому нужно подключаться указан в логах.
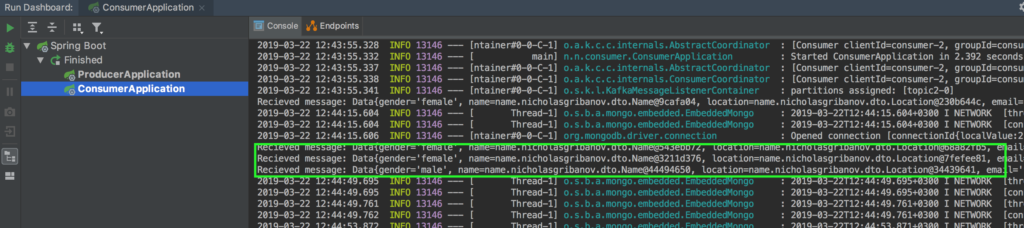
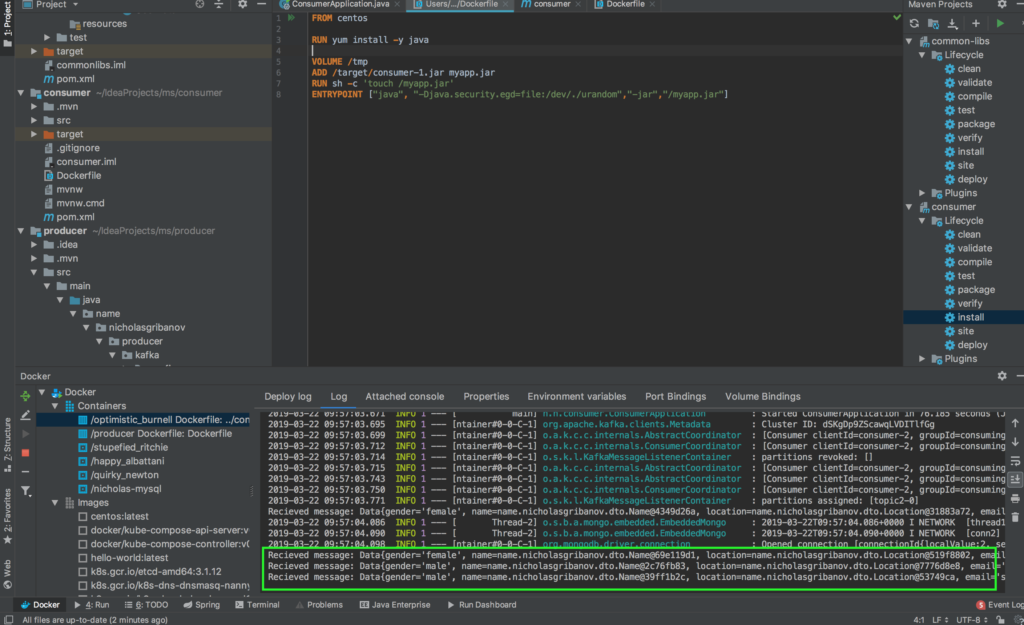
Запустим потребителя данных в контейнере по аналогии с предыдущим микросервисом. Путь тот же самый: создаем Dockerfile, собираем проект, запускаем. Если все сделано правильно, то в логах контейнера вы увидите следующее сообщение:
Выводы
Итак, мы создали два микросервиса: один с помощью Rest получает данные из внешнего источника, упаковывает их в объект и отправляет в Apache Kafka, второй микросервис читает данные из Apache Kafka и сохраняет их в MongoDB. Эти сервисы работают внутри Docker контейнеров.
Бонус
В данном примере мы использовали стандартный Json-сериализатор/десериализатор. Однако, его может вам не хватить. К примеру, если в вашем объекте передается большое количество данных, например, объекты с координатами графика. Таких точек может быть несколько тысяч и json-сериализатор отработает так, что ваш объект будет весить больше 100 мегабайт. При записи такого объекта в Kafka возникнет ошибка, т.к. в стандартной конфигурации сервера Kafka установлено ограничение на 100мб для сообщения. Из этой ситуации есть 3 выхода:
- Объекты, например, графики или любые другие объекты, содержащиеся в большом количестве, нужно предварительно кодировать и сжимать используя, например, base64. При таком подходе мы потеряем визуализацию данных в MongoDB, и для работы других приложений с этими данными нужно использовать декодировку.
- Увеличить размер максимума для сообщений в конфигурации Kafka. Для этого необходимо в файле server.properties изменить число в блоке socket.request.max.bytes.
- Написать для объекта свой собственный сериализатор/десериализатор. Про то что такое сериализация написано здесь.
Предпочтительным является третий путь, потому что он дает нам более гибкий инструмент для управления сериализацией собственных объектов. Реализуем этот путь в наших микросервисах. Для этого нам нужно создать два класса для сериализации и десериализации, реализующих интрефейсы Serializer и Deserializer пакета kafka.common.serialization.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
//DataSerializer.java public class DataSerializer implements Serializer<Data> { private boolean isKey; @Override public void configure(Map<String, ?> map, boolean b) { this.isKey = b; } @Override public byte[] serialize(String s, Data data) { if (data == null) return null; try { ByteArrayOutputStream outputStream = new ByteArrayOutputStream(); ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream); objectOutputStream.writeObject(data); objectOutputStream.flush(); return outputStream.toByteArray(); } catch (IOException e) { throw new SerializationException("Error serializing", e); } } @Override public void close() { } } //DataDeserializer.java public class DataDeserializer implements Deserializer<Data> { private boolean isKey; @Override public void configure(Map<String, ?> map, boolean b) { this.isKey = b; } @Override public Data deserialize(String s, byte[] data) { if (data == null) return null; try { ObjectInputStream objectInputStream = new ObjectInputStream(new ByteArrayInputStream(data)); return (Data) objectInputStream.readObject(); } catch (IOException e) { throw new SerializationException("Error deserialising", e); } catch (ClassNotFoundException e) { throw new SerializationException("Error deserialising", e); } } @Override public void close() { } } |
И подставить новые сериализатор/десериализатор в конфигурационные классы Kafka обоих сервисов.
Исходный код со стандартным json-сериализатором лежит здесь
Исходный код с реализацией собственного сериализатора здесь
ПРИЯТНОГО АППЕТИТА!